CAKE: Cloud Architecture Knowledge Evaluation of Large Language Models
Accepted · KDA-AI Workshop, IEEE ICSA 2026
CAKE: Cloud Architecture Knowledge Evaluation of Large Language Models
Abstract
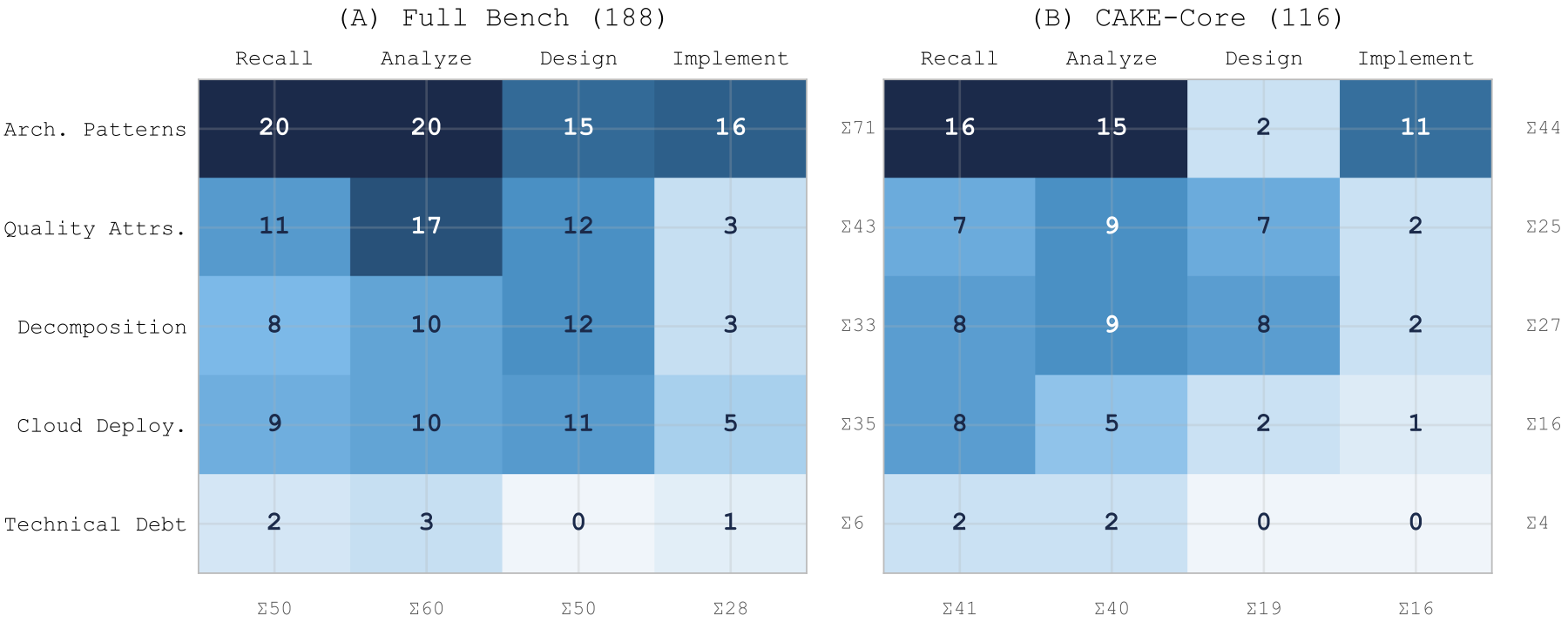
Large language models increasingly serve as software architecture co-pilots, yet no benchmark directly evaluates their understanding of cloud-native software architecture. CAKE addresses this gap with 188 expert-validated questions across four cognitive levels of Bloom's revised taxonomy: recall, analyze, design, and implement.
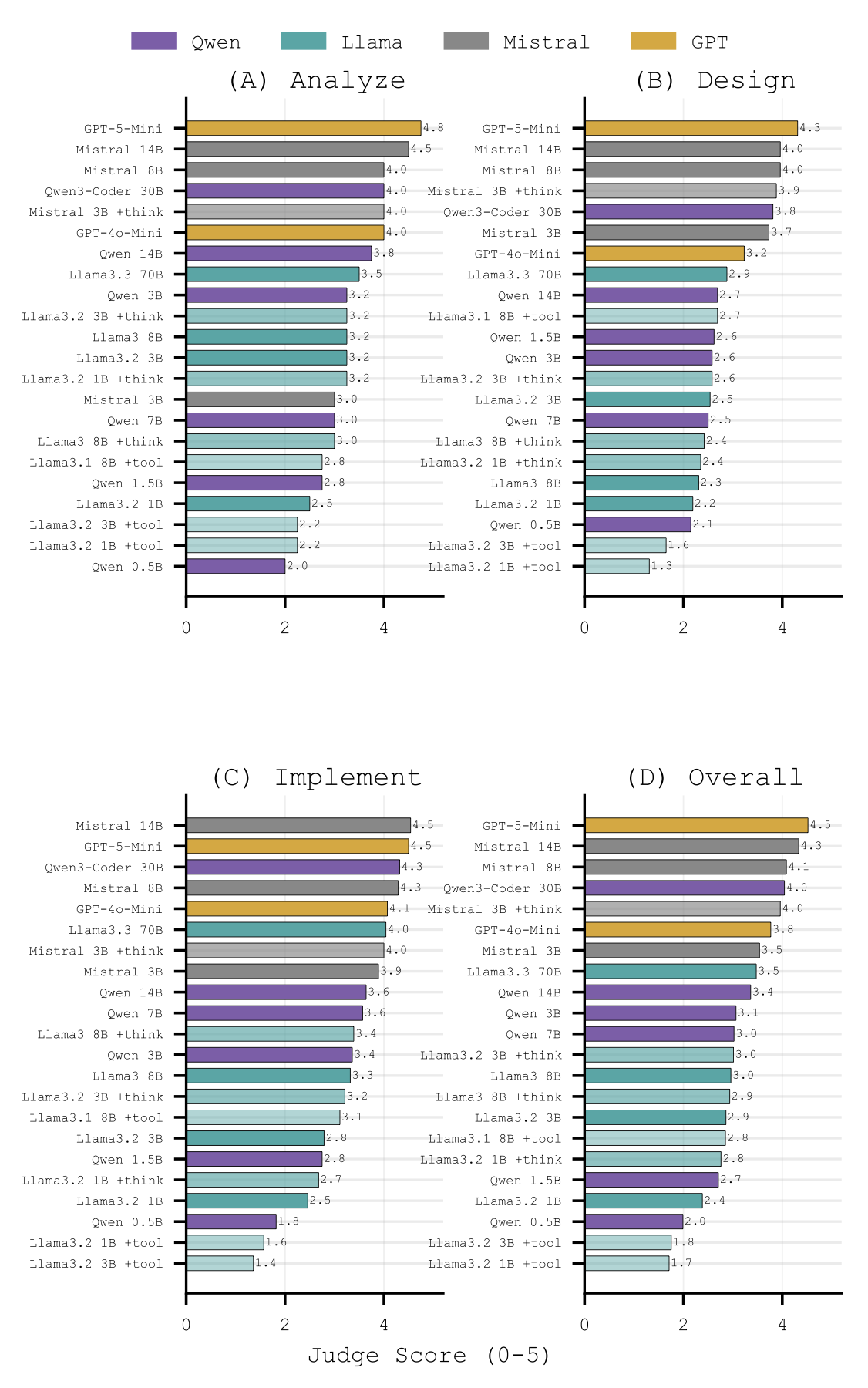
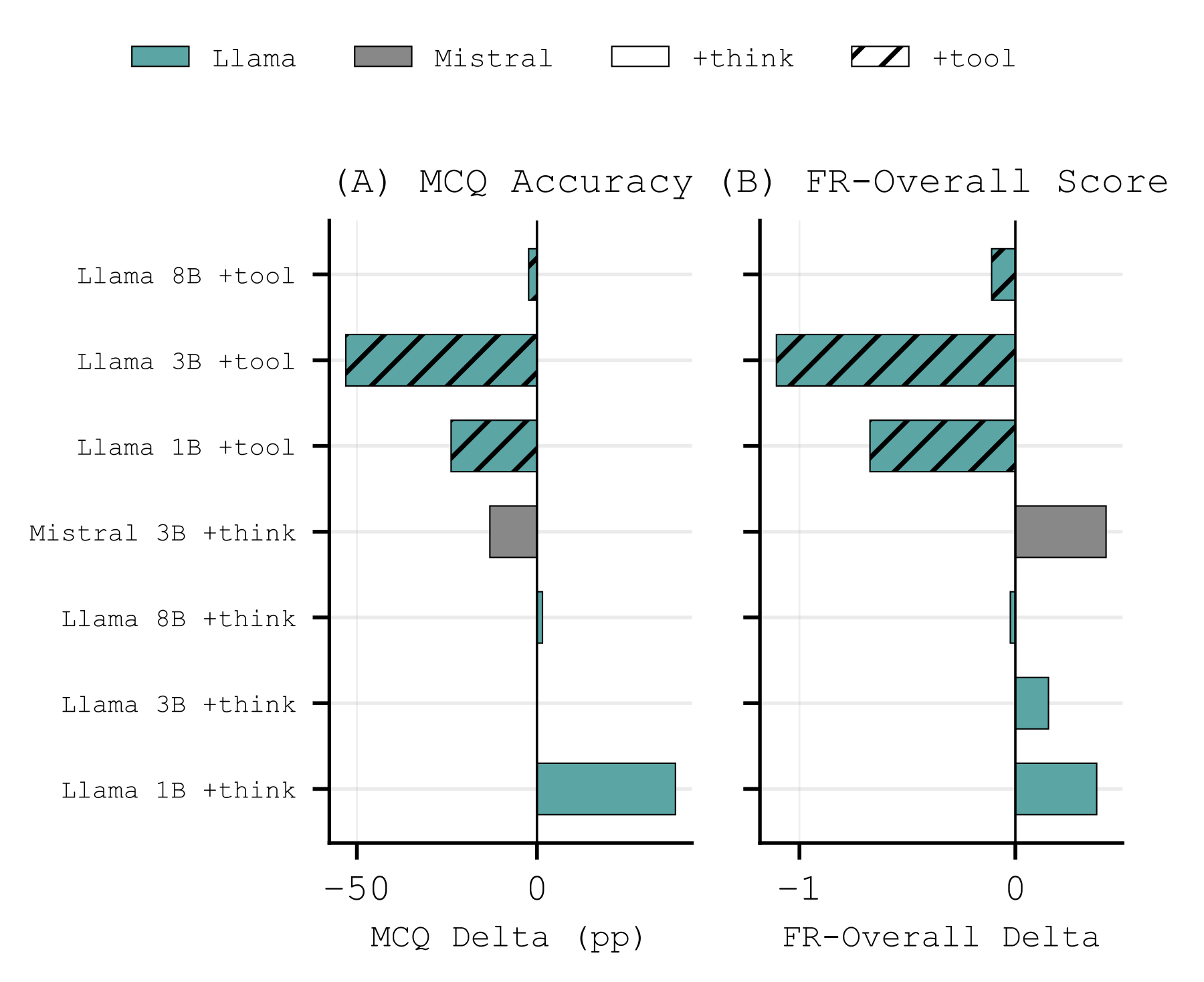
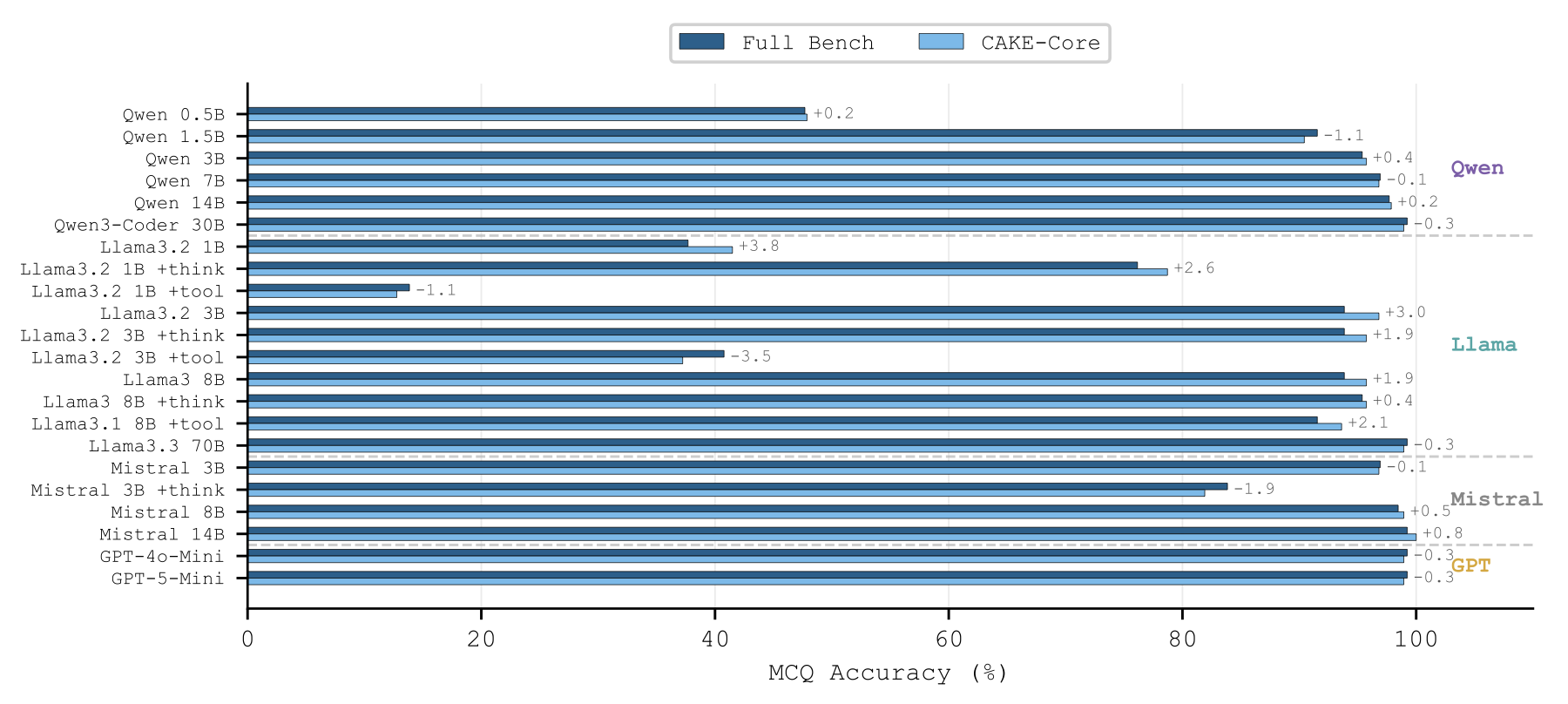
We evaluate 22 model configurations from four LLM families using three-run majority voting for multiple-choice questions and LLM-as-a-judge scoring for free responses. MCQ accuracy plateaus above 3B parameters, while free-response scores continue to separate model capability. Reasoning augmentation improves free-response quality, while tool augmentation degrades performance for smaller models.
Key Findings
MCQ accuracy saturates early
Above roughly 3B parameters, multiple-choice scores approach a ceiling, with the best model reaching 99.2% accuracy.
Free response keeps differentiating
Open-ended architectural answers expose capability gaps that MCQs hide, especially for design and implementation tasks.
Evaluation format changes the story
MCQ and free-response evaluation measure different facets of architectural knowledge and should not be treated as interchangeable.
Augmentation depends on model size
+think improves free-response quality, while +tool harms smaller models and only stabilizes near 8B parameters.
Contributions
- A cloud-native software architecture benchmark with 188 expert-validated questions.
- Coverage across recall, analyze, design, and implement levels from Bloom's revised taxonomy.
- An empirical evaluation of 22 configurations across Qwen, Llama, Mistral, and GPT model families.
- Public benchmark artifacts for evaluating architectural knowledge in LLMs.
Method In Brief
- Questions were generated from cloud-native architecture concepts and expert-reviewed for clarity, correctness, and difficulty.
- MCQs were evaluated with shuffled options and three-run majority voting to reduce positional bias.
- Free-response answers were scored on a deterministic 0-5 rubric using an LLM judge.
- Models were tested in base, structured reasoning, and tool-augmented configurations where available.
Selected Figures